
OTX Frsky Taranis Sound Dateien
- Themenstarter gonzo1981
- Beginndatum
habe gerade das hier gefunden http://winbox.open-tx.org/taranis-sounds-beta1/index.php
Ich möchte als Taranis Neuling auch gerne eine Frage loswerden:
Ich habe mir die Bettina Sprachdateien runtergeladen, auf dei SD Karte kopiert und es funktioniert auch erstmal soweit, die Taranis spricht deutsch!
Soweit so gut!
Nun läuft meine Telemetrie über das LUA-Script und dort wählt "Bettina" die falschen Parameteransagen:
Statt "Prozent" wählt sie "Milliampere", statt "Meter" sagt sie "Milliampere pro Stunde"
In den Sensoren der Telemetriesettings sind die Einheite aber richtig definiert...
Soweit ich den (schon sehr langen) thread überflogen habe , gab es bei anderen auch Probleme mit der richtigen Zurordnung der Soundfiles... Aber wie das zu beheben ist, habe ich nicht verstanden!
Hat jemand eine Tipp für mich?
Ich habe mir die Bettina Sprachdateien runtergeladen, auf dei SD Karte kopiert und es funktioniert auch erstmal soweit, die Taranis spricht deutsch!
Soweit so gut!
Nun läuft meine Telemetrie über das LUA-Script und dort wählt "Bettina" die falschen Parameteransagen:
Statt "Prozent" wählt sie "Milliampere", statt "Meter" sagt sie "Milliampere pro Stunde"
In den Sensoren der Telemetriesettings sind die Einheite aber richtig definiert...
Soweit ich den (schon sehr langen) thread überflogen habe , gab es bei anderen auch Probleme mit der richtigen Zurordnung der Soundfiles... Aber wie das zu beheben ist, habe ich nicht verstanden!
Hat jemand eine Tipp für mich?
OK, das klingt logisch!
Habe 2.1.8 drauf!
Hast Du einen passenden "Bettina-Link" für die Version für mich?
Habe 2.1.8 drauf!
Hast Du einen passenden "Bettina-Link" für die Version für mich?
Etwas versteckt in diesem Monster-Thread:
http://fpv-community.de/showthread....-Sound-Dateien&p=855901&viewfull=1#post855901
Hallo,
Hier sind die Sprachdateien für 2.1.x von der OpenTX-Seite:
http://voices-21.open-tx.org/
Ich selbst nutze für 2.1.x die Sprachdateien von Bettina (Post #166):
http://fpv-community.de/showthread....-Sound-Dateien&p=855901&viewfull=1#post855901
Gruß
meute
Welche deutsche Sprachdateien funktionieren jetzt ohne Probleme ? Oder haben alle bugs ?
http://voices-21.open-tx.org/
Ich selbst nutze für 2.1.x die Sprachdateien von Bettina (Post #166):
http://fpv-community.de/showthread....-Sound-Dateien&p=855901&viewfull=1#post855901
Gruß
meute
Hat jemand eine paar schöne Files für mich, die gut geeignet für Heli sind? Mir fehlen bei Bettina die Ansage für Kreisel, Heck oder ähnliches
schau mal hier
http://fpv-community.de/showthread....-TTSTranslater&p=968193&viewfull=1#post968193
Mit diesem Programm hast du schnell brauchbare Ergebnisse.
Gruß
Es geht auch noch einfacher:
http://winbox.open-tx.org/taranis-sounds-beta1/index.php
mußt halt nur ausprobieren, welche Stimme zu deinem bisherigen Sounds passt.
http://winbox.open-tx.org/taranis-sounds-beta1/index.php
mußt halt nur ausprobieren, welche Stimme zu deinem bisherigen Sounds passt.
Es geht auch noch einfacher:
http://winbox.open-tx.org/taranis-sounds-beta1/index.php
mußt halt nur ausprobieren, welche Stimme zu deinem bisherigen Sounds passt.
http://winbox.open-tx.org/taranis-sounds-beta1/index.php
mußt halt nur ausprobieren, welche Stimme zu deinem bisherigen Sounds passt.
Hallo,
ich habe meine Sounds hier erzeugt:
http://www.acapela-group.com/
Stimme "Claudia" und "Julia".
Erstellt habe ich immer beide Stimmen.
Ich weiß nicht mehr auswendig, welche ich davon nun nutze.
Du musst den Text über die Webseite anhören.
Die Datei kannst Du dann über den Link im Seitenquelltext herunterladen.
Bei Firefox geht das so:
Firefox > Extras > Web-Entwickler > Inspektor > Netzwerkanalyse (Reiter oben) > Medien (Reiter unten)
Dort findest Du den Link zur Datei.
Oder mit dem Add-In Video DownloadHelper herunterladen.
Gruß
meute
ich habe meine Sounds hier erzeugt:
http://www.acapela-group.com/
Stimme "Claudia" und "Julia".
Erstellt habe ich immer beide Stimmen.
Ich weiß nicht mehr auswendig, welche ich davon nun nutze.
Du musst den Text über die Webseite anhören.
Die Datei kannst Du dann über den Link im Seitenquelltext herunterladen.
Bei Firefox geht das so:
Firefox > Extras > Web-Entwickler > Inspektor > Netzwerkanalyse (Reiter oben) > Medien (Reiter unten)
Dort findest Du den Link zur Datei.
Oder mit dem Add-In Video DownloadHelper herunterladen.
Gruß
meute
Hallo zusammen,
ich habe eine Weg gefunden Tante Google für uns sprechen zu lassen.
Der Weg geht wie folgt:
- mit dem Python Package "gTTS" (Goggle Text To Speech) erzeugt man eine MP3 Datei
- diese konvertiert man dann in eine ensprechende wav-Datei (geht auch über Python z.B. in Kombination mit ffmpeg)
Vorteile:
- lässt sich über das Skript voll automatisieren
- beliebige Texte möglich (ich glaube bei 100 Zeichen pro mp3-Datei ist Schluss, dass sollte aber in jedem Fall reichen)
- viele Sprachen verfügbar
Nachteile:
- nur eine Stimme verfügbar
- irgendwo habe ich gelesen, dass das eigentlich nicht mehr kostenlos sein soll und man einen Key benötigt; dass konnte ich bisher aber nicht feststellen
Anbei mal ein paar Beispiele.
VG
Oliver
Anhang anzeigen gTTS.zip
ich habe eine Weg gefunden Tante Google für uns sprechen zu lassen.
Der Weg geht wie folgt:
- mit dem Python Package "gTTS" (Goggle Text To Speech) erzeugt man eine MP3 Datei
- diese konvertiert man dann in eine ensprechende wav-Datei (geht auch über Python z.B. in Kombination mit ffmpeg)
Vorteile:
- lässt sich über das Skript voll automatisieren
- beliebige Texte möglich (ich glaube bei 100 Zeichen pro mp3-Datei ist Schluss, dass sollte aber in jedem Fall reichen)
- viele Sprachen verfügbar
Nachteile:
- nur eine Stimme verfügbar
- irgendwo habe ich gelesen, dass das eigentlich nicht mehr kostenlos sein soll und man einen Key benötigt; dass konnte ich bisher aber nicht feststellen
Anbei mal ein paar Beispiele.
VG
Oliver
Anhang anzeigen gTTS.zip
Hy,
kannste mit TTSAutomate alle Dateien und Verzeichnisse in einem Rutsch machen
da ist auch die Googlestimme drinnen
https://github.com/CaffeineAU/TTSAutomate/releases/tag/2.8.2.6
kannste mit TTSAutomate alle Dateien und Verzeichnisse in einem Rutsch machen
da ist auch die Googlestimme drinnen
https://github.com/CaffeineAU/TTSAutomate/releases/tag/2.8.2.6
Anhänge
-
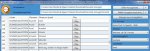 160,5 KB Aufrufe: 26
160,5 KB Aufrufe: 26
Noch als Ergänzung für Mac-Benutzer:
Ich habe mir TTSAutomate angeschaut und unter VirtualBox in Windows laufen lassen. Funktioniert.
Ich finde das für Macuser aber viel zu umständlich, da statt CSV PSV benötigt wird (ich verstehe nicht, warum), die Bedienoberfläche ziemlich langsam läuft (verstehe ich auch nicht) und man einen fremden webbasierten TTS-Provider benutzen muss, da unter Windows keine deutschen Stimmen vorhanden sind.
Auf dem Mac gibt es standardmäßig ein TTS, bei dem 4 deutsche Stimmen (2 männlich, 2 weiblich) verfügbar sind. Die Stimmen muss man in den Systemeinstellungen "Bedienungshilfen/Sprachausgabe" mit dem Popupmenü "Systemstimme/Anpassen..." konfigurieren/herunterladen. Im Terminal reicht einfach der Befehl say "Irgendein Text", um Text auszugeben. Dieser kann auch in verschiedenen Formaten direkt als Datei gespeichert werden.
D.h. der Mac bringt von Haus aus schon die benötigten Fähigkeiten (einlesen und auswerten der CSV, erzeugen der Sprachdateien) mit und man muss nur in Automator oder als Shellskript einen kleinen Workflow schreiben, um das zu automatisieren und alle Sounds in einem Rutsch zu erzeugen.
Jetzt hat sich schon jemand hingesetzt und diese Skripte geschrieben:
https://github.com/RCdiy/OpenTxSounds/tree/master/Mac Apps Scripts
Dort liegen 4 Sachen:
"Sound Pack generator.app": Ein Programm, dass eine CSV einliest und auf einen Rutsch alle enthaltenen Sounds erzeugt und in den richtigen Ordnern ablegt.
"SoundPackGenerator.sh": Ein Shellskript, dass eine CSV einliest und auf einen Rutsch alle enthaltenen Sounds erzeugt und in den richtigen Ordnern ablegt.
"Text To Wav.app": Ein Programm, dass einen Text abfragt und in einen Sound umwandelt.
"TextToWav.sh": Ein Shellskript, dass einen text in einen Sound umwandelt.
Die beiden Programme und TextToWav.sh haben leider den Nachteil, dass die Verwendung von Tessa als Stimme (englisch) eingetragen ist. Das Shellskript kann man in jedem Texteditor ändern und einfach die deutsche Stimme eintragen. Die beiden Programme sind eigentlich Automatorskripte und können in Automator geöffnet werden. Dort die verwendete Stimme ändern und speichern. In dem Shellscript "SoundPackGenerator" wird schon die richtige Stimme anhand der Länderkennung ausgewählt.
Klingt jetzt alles komplizierter als es ist. Hat man die deutsche Stimme eingetragen, kann man direkt die CSV von OpenTX nehmen, das Skript laufen lassen und alles wird lokal und in guter Qualität in einem Rutsch erzeugt.")
Ich habe mir TTSAutomate angeschaut und unter VirtualBox in Windows laufen lassen. Funktioniert.
Ich finde das für Macuser aber viel zu umständlich, da statt CSV PSV benötigt wird (ich verstehe nicht, warum), die Bedienoberfläche ziemlich langsam läuft (verstehe ich auch nicht) und man einen fremden webbasierten TTS-Provider benutzen muss, da unter Windows keine deutschen Stimmen vorhanden sind.
Auf dem Mac gibt es standardmäßig ein TTS, bei dem 4 deutsche Stimmen (2 männlich, 2 weiblich) verfügbar sind. Die Stimmen muss man in den Systemeinstellungen "Bedienungshilfen/Sprachausgabe" mit dem Popupmenü "Systemstimme/Anpassen..." konfigurieren/herunterladen. Im Terminal reicht einfach der Befehl say "Irgendein Text", um Text auszugeben. Dieser kann auch in verschiedenen Formaten direkt als Datei gespeichert werden.
D.h. der Mac bringt von Haus aus schon die benötigten Fähigkeiten (einlesen und auswerten der CSV, erzeugen der Sprachdateien) mit und man muss nur in Automator oder als Shellskript einen kleinen Workflow schreiben, um das zu automatisieren und alle Sounds in einem Rutsch zu erzeugen.
Jetzt hat sich schon jemand hingesetzt und diese Skripte geschrieben:
https://github.com/RCdiy/OpenTxSounds/tree/master/Mac Apps Scripts
Dort liegen 4 Sachen:
"Sound Pack generator.app": Ein Programm, dass eine CSV einliest und auf einen Rutsch alle enthaltenen Sounds erzeugt und in den richtigen Ordnern ablegt.
"SoundPackGenerator.sh": Ein Shellskript, dass eine CSV einliest und auf einen Rutsch alle enthaltenen Sounds erzeugt und in den richtigen Ordnern ablegt.
"Text To Wav.app": Ein Programm, dass einen Text abfragt und in einen Sound umwandelt.
"TextToWav.sh": Ein Shellskript, dass einen text in einen Sound umwandelt.
Die beiden Programme und TextToWav.sh haben leider den Nachteil, dass die Verwendung von Tessa als Stimme (englisch) eingetragen ist. Das Shellskript kann man in jedem Texteditor ändern und einfach die deutsche Stimme eintragen. Die beiden Programme sind eigentlich Automatorskripte und können in Automator geöffnet werden. Dort die verwendete Stimme ändern und speichern. In dem Shellscript "SoundPackGenerator" wird schon die richtige Stimme anhand der Länderkennung ausgewählt.
Klingt jetzt alles komplizierter als es ist. Hat man die deutsche Stimme eingetragen, kann man direkt die CSV von OpenTX nehmen, das Skript laufen lassen und alles wird lokal und in guter Qualität in einem Rutsch erzeugt.

